
다양한 크기의 데이터 세트에 대해 C 도표 사용하기
여러분,
C 도표는 속성 데이터를 추적하는 데 사용되는 제어 도표예요. 예를 들어, SMT 어셈블리 공정이 끝날 때 불량을 추적한다고 가정해 보죠. 경영진은 10,000 개의 어셈블리당 몇 개의 불량이 있는지 알고 싶다고 언급했어요. 따라서 여러분은 제조된 10,000 개의 어셈블리마다 불량 수를 추적해요. 선임 공정 엔지니어로서, 이러한 속성 데이터를 6개월 동안 수집했다고 가정해 보겠습니다. 분석을 간단하게 하기 위해, 매일 조립되는 어셈블리의 수를 가정해 보죠. 데이터의 C 도표는 도표 1에 나와 있어요. 언급된 슈하트 규칙 1 위반은 거의 공통적인 원인 위반에 의한 것이에요.
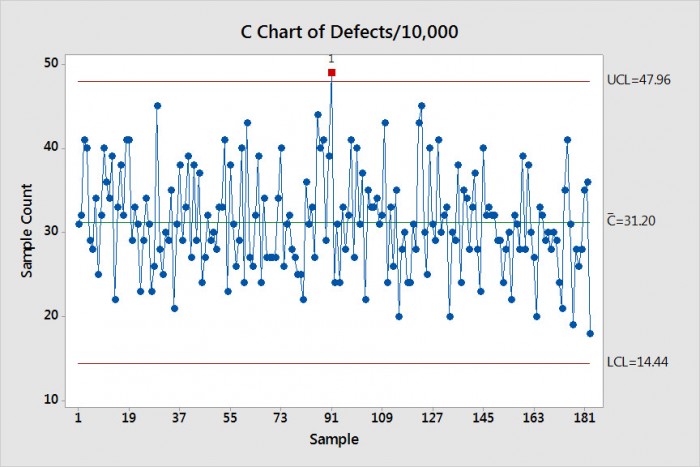
도표 1. C 도표 10,000 의 데이터 세트에 대한 데이터.
여러분은 2주간의 휴가를 떠나고 과로하는 동료 중 일부는 라인을 모니터링할 것을 동의하고 속성 데이터를 수집하죠. 안타깝게도, 여러분의 부재로 인해서, 어셈블리 라인에서 몇 가지 공정 문제가 있어요. 결과적으로, 매일 5,000 개의 어셈블리만 생산되고 있어요. 경영진은 새 데이터를 이전 데이터와 비교하려고 하지만 샘플 크기가 달라요. 5,000개당 불량 수를 표본 크기의 비율로 단순히 곱하면 되는데, 이 경우 비율은 2 (10,000/5,000) 예요. 이러한 새로 수정된 데이터를 이전 데이터에 추가하여 업데이트된 C 도표를 그릴 수 있어요. 우리의 경우, 처음 3일 동안 불량 데이터는 5,000개 어셈블리당 31, 23 및 21개의 불량이었어요. 2를 곱하면, 이 데이터 포인트는 이제 62, 46 및 42가 돼요. 2주분의 데이터에 대해 이 간단한 작업을 수행하고 이를 이전 C 도표 결과에 추가하면 그림 2의 새로운 C 도표가 생성되죠.
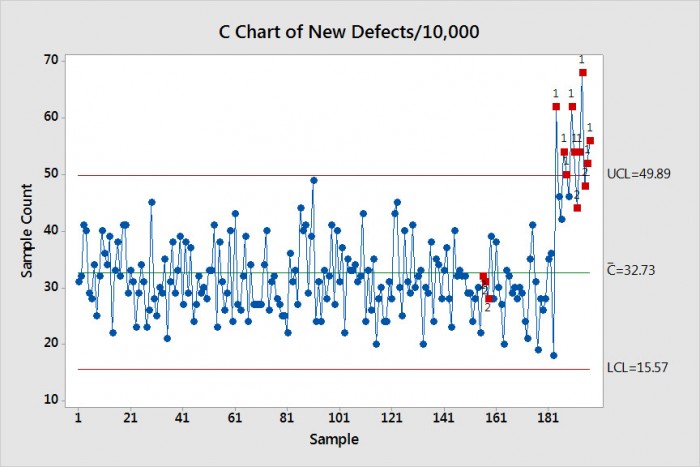
도표 2. 새 데이터 세트의 각 오류 수에 2를 곱하여 새 데이터를 이전 데이터에 추가하고 새 C 도표를 생성할 수 있어요. 새 데이터에 대한 불량률은 많은 슈하트 규칙 1 위반에 의해 입증된 것보다 커요.
새 데이터는 많은 슈하트 규칙 1 위반 사항에 명시된 것처럼 높은 불합격율을 명확하게 보여주죠. 이 결과는 어셈블리 공정을 지원하기 위해서 해야만 하는 좋은 작업을 강력하게 뒷받침하고 있어요. 생산량이 50 % 감소했을 뿐만 아니라, 여러분의 부재시에 불량률이 상당히 높아졌어요.
저는 이러한 데이터 변환을 만들기 위해서 엑셀 스프레드 시트를 개발했어요. 관심이 있으시면, 저에게 이메일을 보내 주시면 스프레드 시트를 보내 드릴께요.
감사합니다,
론 박사
Connect with Indium.
Read our latest posts!